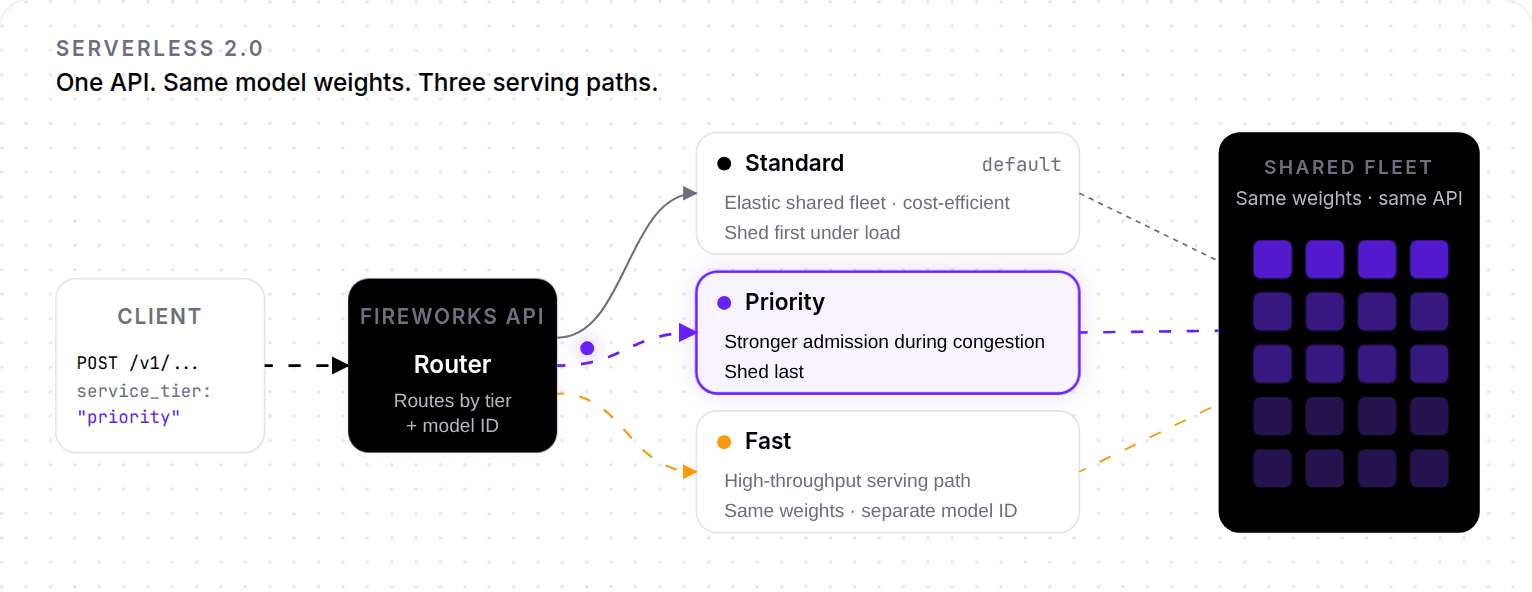
GLM 5.2 Fast is live on Fireworks today. Across multiple 3rd party benchmarks, Fireworks consistently delivers the fastest throughput among all API inference providers. ~2x our own Standard path, on shared serverless endpoint, available for everyone, with no reserved GPUs.